安装排障¶
本页汇总了常见的安装问题及排障方案,便于用户快速解决安装及运行过程中遇到的问题。
UI 访问问题¶
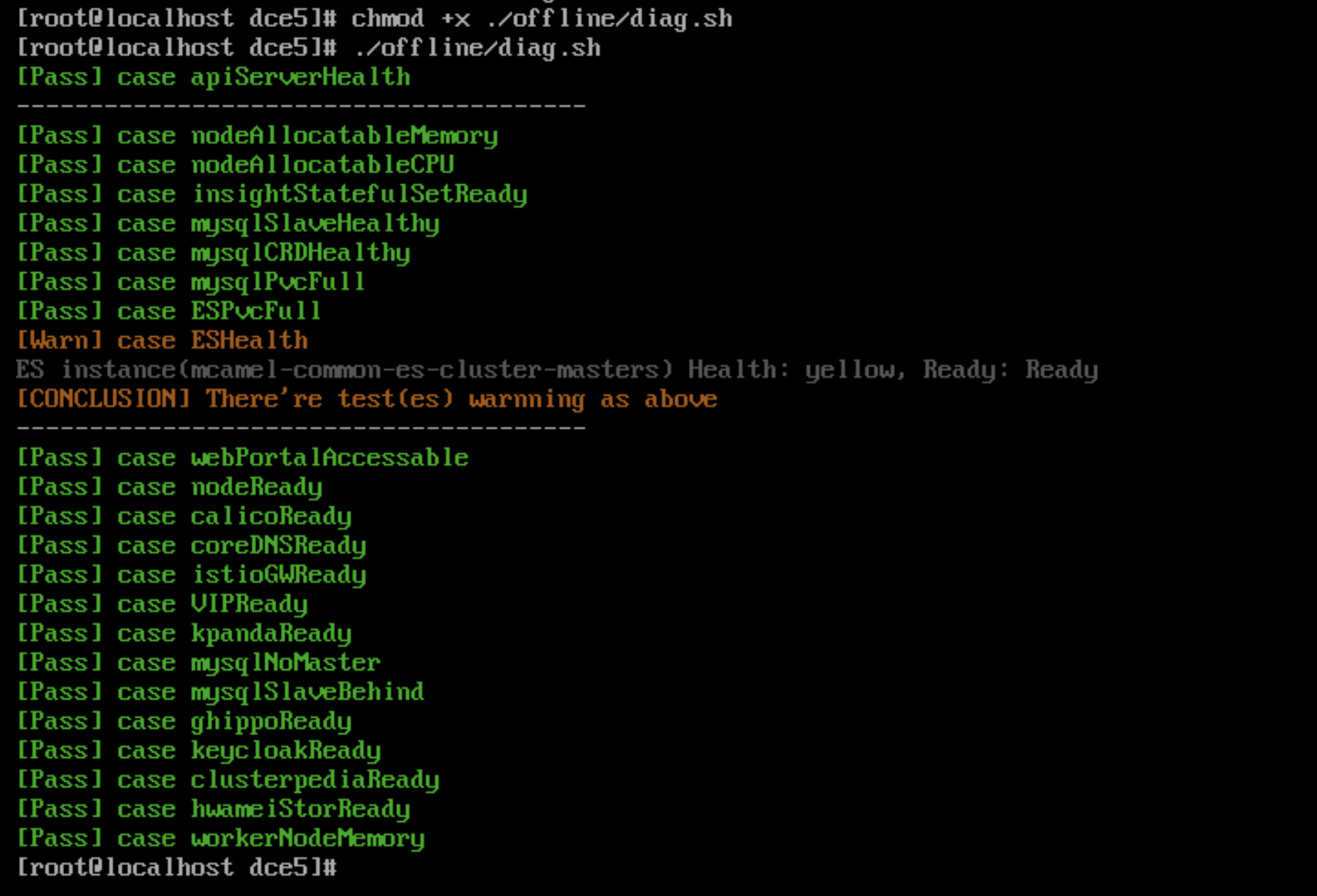
DCE 5.0 界面打不开时,执行 diag.sh 脚本快速排障¶
安装器自 v0.12.0 版本之后新增了 diag.sh 脚本,方便用户在 DCE 5.0 界面打不开时快速排障。
执行命令:
执行结果示例:
使用 Metallb 时 VIP 访问不通导致 DCE 登录界面无法打开¶
- 排查 VIP 的地址是否和主机在同一个网段,Metallb L2 模式下需要确保在同一个网段
-
如果是在全局服务集群中的控制节点新增了网卡导致访问不通,需要手动配置 L2Advertisement。
请参考 Metallb 这个问题的文档。
火种节点问题¶
火种节点关机重启后,kind 集群无法正常重启¶
火种节点关机重启后,由于部署时在 openEuler 22.03 LTS SP2 操作系统上未设置 kind 集群开机自启动,会导致 kind 集群无法正常开启。
需要执行如下命令开启:
Note
如果其他环境中发生了上述场景,也可以执行该命令进行重启。
Ubuntu 20.04 作为火种机器部署时缺失 ip6tables¶
Ubuntu 20.04 作为火种机器部署,由于缺失 ip6tables 会导致部署过程中报错。
请参阅 Podman 已知问题。
临时解决方案:手动安装 iptables,参考 Install and Use iptables on Ubuntu 22.04。
禁用 IPv6 后安装时,火种节点 Podman 无法创建容器¶
报错信息如下:
解决方案:重新启用 IPv6 或者更新火种节点底座为 Docker。
参阅 Podman 相关 Issue: podman 4.0 hangs indefinitely if ipv6 is disabled on system
火种节点 kind 容器重启后,kubelet 服务无法启动¶
kind 容器重启后,kubelet 服务无法启动,并报以下错误:
解决方案:
-
方案 1:重启,执行命令
podman restart [kind] --time 120,执行过程中不能通过 Ctrl+C 中断该任务 -
方案 2:运行
podman exec进入 kind 容器,执行以下命令:
如何卸载火种节点的数据¶
商业版部署后,如果进行卸载,除了本身的集群节点外,还需要对火种节点进行重置,重置步骤如下:
需要使用 sudo rm -rf 命令删除这三个目录:
- /tmp
- /var/lib/dce5/
- /home/kind/etcd
证书问题¶
全局服务集群的 kubeconfig 在火种的副本需要更新¶
v0.20.0 之前的版本中,火种机上存储的全局服务集群的 kubeconfig 不会自动更新,v0.20.0 版本支持了自动更新,每个月执行一次。
之前的版本需要将 dce5-installer 更新到 v0.20.0 然后执行:
火种节点的 kind 集群本身的证书更新以及 kubeconfig¶
v0.20.0 之前的版本中,火种机上存储的 kind 集群的 kubeconfig 不会自动更新,v0.20.0 版本支持了自动更新,每个月执行一次。
之前的版本需要将 dce5-installer 更新到 v0.20.0 然后执行:
Contour 安装后,证书默认有效期仅一年,且不会自动 renew,过期后导致 contour-envoy 组件不断重启¶
v0.21.0 之前的版本,支持启用安装 Contour 组件,后续版本将不再支持,对于之前版本并且安装了 Contour 的客户,需要执行 helm upgrade 命令来更新证书有效期:
helm upgrade -n contour-system contour --reuse-values --set contour.contour.certgen.certificateLifetime=36500
操作系统相关问题¶
在 CentOS 7.6 安装时报错¶
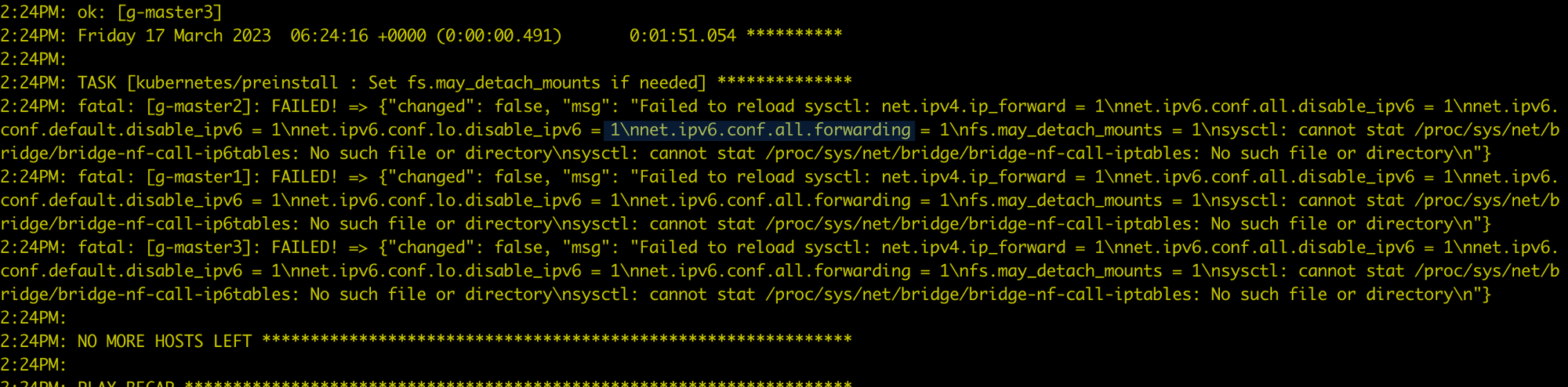
在安装全局服务集群的每个节点上执行 modprobe br_netfilter,将 br_netfilter 加载之后就好了。
CentOS 环境准备问题¶
运行 yum install docker 时报错:
Failed to set locale, defaulting to C.UTF-8
CentOS Linux 8 - AppStream 93 B/s | 38 B 00:00
Error: Failed to download metadata for repo 'appstream': Cannot prepare internal mirrorlist: No URLs in mirrorlist
可以尝试下述方法来解决:
-
安装
glibc-langpack-en -
如果问题依然存在,尝试:
社区版问题¶
kind 集群重装 DCE 5.0 时 Redis 卡住¶
问题:Redis Pod 出现了 0/4 running 很久的情况,提示:primary ClusterIP can not unset
-
在
mcamel-system命名空间下删除 rfs-mcamel-common-redis -
然后重新执行安装命令
社区版 fluent-bit 安装失败¶
报错:
排查 Pod 日志是否出现下述关键信息:
[warn] [net] getaddrinfo(host='mcamel-common-es-cluster-masters-es-http.mcamel-system.svc.cluster.local',errt11):Could not contact DNS servers
出现上述问题是一个 fluent-bit 的 bug,可以参考 aws/aws-for-fluent-bit 的一个 Issue:
Seeing Timeout while contacting DNS servers with latest v2.19.1